 HubSpot
HubSpot
 Salesforce
Salesforce
.png?width=58&height=58&name=Frame%202087327944%20(1).png) GA4
GA4
.png?width=58&height=58&name=Frame%202087327944%20(2).png) Marketo
Marketo
.png?width=58&height=58&name=Frame%202087327944%20(3).png) Audit Fox
Audit Fox
Personalization and segmentation are a lot like making the perfect playlist: get it wrong, and your audience checks out; get it right, and every message hits the spot.
This month, we’re digging into how modern RevOps teams can slice, dice, and serve content that clicks with the audience, and how the right approach turns scattered data into revenue-ready insights.
Inside this Newsletter:
✅ Blog: Your personalized emails deserve better than the spam folder
✅ Blog: Is your outdated homepage making leads go away?
✅ HubSpot update: The new blog research agent unlocks the infinite blog idea glitch 😵
✅ HubSpot update: Your customer agent can now do stuff on its own!
✅ Case study: How Orchestrated Connecting brought more value to its 2000+ member network with their email campaign
✅ RevXpert Academy: Scale personalized outreach with HubSpot sequences
Blogs
Your personalized emails are ending up in spam. They don’t need to.
.webp?width=915&height=498&name=Gemini_Generated_Image_82kua382kua382ku%20(1).webp)
You know that feeling when you get a “personalized” email that’s clearly sent to a thousand others? Yeah, your prospects do too. In this blog, we dive into why most segmentation efforts miss the mark and how to actually make your campaigns feel personal. With better data, sharper segments, and smarter content, you can turn “Hey {First Name}” into “Wow, you actually get me!”
A slow homepage could be stealing your leads. But you don’t have to stand and look.
.webp?width=915&height=498&name=Homepage%20(1).webp)
Think your homepage is just “there”? Think again. Every unclear headline, slow load, or missing CTA is quietly letting leads slip through the cracks. In this blog, we show how to turn that wallflower of a homepage into a revenue-generating machine. Speed up conversions, guide visitors where they need to go, and make sure your site actually works as hard as you do.
HubSpot updates
HubSpot users may never run out of blog ideas again 🤔

Ever stare at a blank page and just want to run for the hills? HubSpot's new Blog Research Agent can be your always-on content strategist. It researches topics, suggests SEO-friendly titles and keywords, drafts blog outlines (even full posts), and spots gaps in your existing content. Just plug in your goals or keywords, and watch it churn out blog-ready ideas at once. Now your writers can focus on polishing instead of starting from scratch.
Your Customer Agent Just Learned to Push Buttons (Literally)
Your customer agent just leveled up: it can now actually do stuff! Think password resets, order lookups, billing checks, or any simple task tied to your apps. Just describe the action, add trigger phrases, set inputs (like account ID or email), connect the API, and the agent takes it from there. No more handoffs for routine requests. It’s now a real task-doing machine for all Pro+ customers.
Case study
How personalization made connections stick for Orchestrated Connecting

Orchestrated Connecting wanted emails that truly resonated with their 2,000-member network. By introducing personalized messaging and strategic CTAs, RevX helped transform their email campaigns into engaging, action-driven communications. Members felt seen, valued, and motivated to participate, leading to higher open rates, more clicks, and stronger event attendance. Personalization didn’t just improve metrics. It strengthened relationships, creating a community where meaningful connections could thrive.
Blogs
Should RevOps report to the CFO?

At RevX, one of our clients had a seemingly straightforward problem: their CFO didn't trust the pipeline data.
The data wasn't wrong (we checked). The problem was that by the time revenue updates reached the CFO, they'd passed through enough interpretations that finance couldn't confidently trust and build decisions on.
The fix wasn't a reporting structure change. It was much simpler, really: automated Slack notifications to the CFO. The result: the CFO trusted the numbers, and could explain the story behind them to the CEO, board member, or investor who asked.
That detail is worth sitting with. Because the dominant conversation about revenue operations and the CFO focuses on a different question: where should RevOps sit? Should it report to the CFO, the CRO, or operate independently?
The assumption underneath is that getting the reporting line right is what produces the alignment. Fix the hierarchy, and data credibility, cross-functional trust, and pipeline accuracy will follow.
They don't. Not automatically, at least.
This is not to say that the reporting line doesn't matter. But it's downstream of a set of conditions that an org chart can't create on its own.
Shreyansh Surana, a RevOps expert with experience across 200+ companies, Adam Chen, CRO at FinStrat Management, and Shane Pahl, Head of RevOps at FinStrat Management, have all built and run revenue operations in organizations at different stages.
None of them land on a clean org chart answer. But what they do arrive at is considerably more useful.
RevOps is a coordination function
It's what brings marketing, sales, and customer success together. Not just the teams, but processes, platforms, and data supporting each of them.
Everyone knows this, but being specific about what that means matters because without shared clarity here, the debate about where RevOps should sit becomes an argument about org chart boxes.
Shreyansh Surana, a RevOps veteran, frames it around three pillars:
"One is process, which includes process and people. That function defines what processes exist across all three revenue departments. Then there is platform, or tech, because modern marketing and sales cannot be done without proper tech alignment. And RevOps doesn't just own the platform, it owns adoption. And then comes the data, because that's what everyone is looking for. Are they blindfolded, or do they know where they are heading? Data tells you that."
But Adam Chen, CRO at FinStrat Management, adds a critical fourth pillar: finance.
In his experience working with early-stage companies, the CFO has often been treated as a financial auditor of revenue rather than a stakeholder in how it gets built. That gap creates its own silo. Marketing, sales, customer success, and finance all feed into the same outcomes, and leaving any one of them out means the alignment is incomplete.
Shane Pahl, Head of RevOps at FinStrat Management, captures the problem RevOps is built to solve in a specific image:
"Take revenue silos, turn them all into rockets. Those are the various departments of a business, all trying to take off and accelerate as fast as possible. Now, insert AI. All of those rockets are now on steroids. People are very experimental with different systems to try to accelerate work. Where does RevOps come into play? RevOps is the coordination between those rockets. It straps them together in a way that creates transparency, with information communicated across each of the silos, and ultimately heading towards the financial realities the business needs to meet."
The word that carries the most weight in Shane's description is "coordination."
RevOps creates value by operating between teams, not from inside any one of them. That distinction is exactly what makes the question of where it reports so structurally loaded.
Addressing a hard question
The reporting debate assumes RevOps is already the right solution for the problem at hand. Often, it isn't. Not because RevOps doesn't work, but because the conditions that make it work haven't been created yet.
Shane Pahl puts it plainly:
"Clients come to us saying they need RevOps help. And they're right, in quite a few cases. But the problem starts way before we get to RevOps. It starts with understanding your customer, understanding your go-to-market processes, and really having maximized those elements before getting to RevOps. That's where you start to see your tools and your CRM come into place, your data hygiene, and making all of that super efficient. The biggest gap is a clear understanding of what the problem is and how you're going to address it before adding technology."
RevOps optimizes a process. It doesn't create one. If the underlying go-to-market motion is unclear, building out a RevOps function creates a clean system for tracking an unclear strategy.
The basic questions need answers first: who you're selling to, how you're reaching them, what a qualified lead looks like in your specific context.
Picture a B2B SaaS company 18 months in, with a handful of customers and some early traction. They bring in a RevOps hire, set up their CRM, and build attribution dashboards.
Six months later, pipeline metrics look organized but conversion is flat. When the team digs in, it turns out marketing has been nurturing mid-market prospects while the founders have been manually closing enterprise deals on the side. Nobody documented the ICP. Nobody agreed on the sales motion.
RevOps gave them a clean system for running two strategies simultaneously, and neither had the full weight of the organization behind it. That's a GTM problem, and RevOps cannot fix it.
For companies that have done the foundational GTM work, the reporting debate becomes real and worth having in earnest.
Whoever owns RevOps, biases it
Reporting lines determine hierarchy. But critically, they shape priorities, and priorities shape output. For a function whose entire value comes from spanning multiple teams, that creates a real problem.
When RevOps is placed inside a single department's structure, it gradually starts serving that department's agenda. Not through bad intent, but through the natural mechanics of how teams work. Requests come from one direction, performance signals come from one direction, and over time, the function bends toward them.
Shreyansh is direct about why this matters:
"RevOps reporting to one particular team brings a lot of bias in their decision-making, and that is what people are realizing. When RevOps takes inputs from sales on their goals, takes inputs from marketing on their goals, and brings that data to a CFO who then does the whole revenue planning, that's where the RevOps team stands. RevOps reporting to one of them is not a very sustainable path. They should be independent, without any biases, keeping all those teams true to the data."
The bias shows up in concrete ways depending on which team holds the reporting line.
When RevOps sits under marketing
The pull toward attribution becomes hard to resist. Marketing's primary accountability is proving the value of its activities, which means RevOps gets drawn into tracking, tagging, and reporting on every campaign, event, and content asset.
Shane has experienced this directly:
"If RevOps were to exclusively report into the CMO, I just see us being dragged much more in that direction, working to validate and prove to everyone that the activities we were doing are actually resulting in more activities. Who has ever heard of meetings booked as a great KPI? At the end of the day, it's about what outcomes we're actually trying to drive."
Time spent building attribution reports for low-leverage activities is time not spent on the process and data work that actually drives revenue outcomes.
When RevOps sits under sales or the CRO
The pull is different but equally distorting. Sales organizations are built around closing, which means the data that gets prioritized is the data that supports the pipeline narrative. Definitions get stretched, stage criteria get loosened, and the numbers that reach leadership reflect optimism more than reality.
Shreyansh points to something as basic as lead qualification to illustrate how deep this goes. Organizations can operate for years without a shared definition of what an MQL is versus an SQL. That's not a technology problem. It's an alignment problem, and it persists precisely because no team with sufficient neutrality owns the question. When RevOps sits inside sales, it inherits sales' answers. And those answers aren't neutral.
The downstream consequence matters: the CFO takes these numbers to the board. If the data has been shaped by any one team's priorities, its credibility is already compromised before it leaves the building.
CFOs don't need to own RevOps; they need to trust it
The natural response to a data credibility problem is to centralize control. The thinking goes: Give the CFO ownership of RevOps and the numbers become reliable.
But ownership and trust are different things, and pursuing one doesn't automatically produce the other.
What the CFO actually needs is confidence in the numbers they're working with. The pipeline data they present to the board, investors, and lenders informs hiring decisions, financial models, fundraising narratives, and strategic commitments.
Adam puts it plainly:
"The CFO is presenting those numbers to the board, making financial decisions, hiring decisions, advising the CEO based on what the company expects to win in the future. If you don't have trust and immense faith in the pipeline numbers and the forecasts, and clear definitions of what a sales qualified lead is, you're going to be operating from an incomplete data set. If you present poor numbers to your investors and your stakeholders and you lose that trust, good luck getting it back."
RevOps independence is what produces data the CFO can trust. Ownership isn't the same thing. A RevOps function shaped by sales optimism or marketing attribution priorities generates numbers the CFO can't confidently defend. Making the function neutral is what fixes that, not handing the CFO a new reporting line.
What this actually looks like in practice
Shreyansh offers a concrete example of what genuine CFO integration looks like without a formal reporting relationship.
For one of his clients, he built a dedicated Slack channel between RevOps and the CFO, paired with an automation: any time a deal amount changes in the CRM, a notification fires directly to the CFO. Not to the sales head first. Directly to the CFO.
"The CFO is getting real-time data and can update their dashboard accordingly, because you never know when a CFO needs to present data to a board, a VC, or somewhere else. The CFO came back and said, 'Now I trust my data.' Because they're getting daily notifications, changes, reasons why those changes are happening, the predictability around it. They're able to narrate the story on why that data looks the way it does."
The CFO didn't gain ownership of RevOps. But they did gain something more important: visibility. And the outcome was the same thing ownership was supposed to produce: trust in the numbers.
That's the distinction worth holding onto. The goal isn't for the CFO to manage RevOps. The goal is for the CFO to never be surprised by the numbers.
A well-designed data feed achieves that. A reporting line might too, but it brings the bias problem along with it.
Two conclusions worth considering
The case for RevOps independence holds, with one important caveat. At pre-seed through Series B, the organizational context looks different enough that the independence argument has to be applied carefully.
There often isn't a fully built-out marketing function, a separate sales team, and a customer success org to align. There's a founder still doing most of the selling, a first hire or two, and a CFO function being handled by the CEO or an outsourced partner. The clean independence model assumes organizational maturity that early-stage companies are still building toward.
The case for CFO alignment
Adam Chen has spent his career working with companies at exactly this stage, and his view is direct:
"RevOps should report into the CFO at the early stages, or whoever that de facto CFO role is sitting with. Maybe it's the CEO at that point. Leading indicators can take you off course. What we advise our early-stage companies on is efficient growth: being capital efficient, using limited resources to extend your runway. Every activity, every time spent, every inefficient interaction between two departments within your org is just drawing down your funds."
His reasoning comes down to what early-stage companies can't afford to get wrong. At that stage, every misalignment between teams has a direct cost. Runway is finite, and bad data is more expensive when there's no organizational buffer to absorb it. Keeping RevOps close to whoever holds the financial mandate grounds the function in the realities that actually govern the business.
The case for COO or CTO alignment
Shane Pahl has also sat directly under a CFO in a RevOps capacity, and his experience points somewhere different:
"As someone who's also sat directly under the CFO, with them being the primary driver of RevOps activities, a lot of times that can work against best practice. They're used to looking at balance sheets, income statements, and statements of cash flows. Those are high-level indicators of business health. That sometimes gets too far away from the activities on the ground we need to drive to make revenue more efficient.
In my experience, I've gotten the best outcomes when I've been aligned with the COO or CTO, because they really understand what it takes to build something. They understand a sprint, and they understand how to guard that sprint so you can actually get things done. Otherwise, you're just constantly getting the Bible-thumping pressure from the CFO: more revenue, more revenue. And it's like, yeah, we get it, we're working towards that, but we have to get this sprint out of the way first in order to actually realize that for you."
The problem Shane describes is the CFO's frame of reference, not their goals. A CFO working from financial statements is operating at a level of abstraction that doesn't map well onto the ground-level implementation work RevOps actually does.
The COO or CTO, by contrast, thinks in systems and delivery. They know what it costs to build something properly, and they can create the space for RevOps to do that without constant revenue pressure overriding the work.
Both positions are grounded in real experience. The tension between them is instructive: the title of the reporting leader matters less than whether that person has the operational depth to give RevOps what it needs: protected capacity, clear scope, and a mandate that doesn't get bent toward one team's priorities. At early stage, finding those qualities in a person is the real decision.
The org chart is where you document all of this, not where you discover it.
The answer isn't tied to org charts
Shreyansh lands on an unambiguous position: RevOps should not report to the CFO, and it should not report to the CRO or CMO either. It should be an independent function. One that can start inside one of those teams if necessary, but builds toward operating as what Shane calls a "wellness coach" across all of them. The value comes from the neutrality, and neutrality requires independence.
But realistically, independence isn't a switch you flip. It's a condition you build toward, and it's built in a specific order.
Adam's captures this well:
"You've got to know who you're targeting, how you're reaching them, and what messaging you have. All of that is foundational. Only then can you think about the tool sets to operationalize those people and those processes. That's where you find the efficiency. If we keep thinking about it in that order, there's no universal answer to where RevOps sits. It's what makes most sense for your people, your organization, and your processes."
People and process clarity first. Technology and operational infrastructure second. The reporting question, by the time you've done that work properly, is less a philosophical debate and more a practical decision about where the function fits best given who's already in the room.
When RevOps has done the foundational work well, it gives the CFO exactly what they need without requiring a formal reporting relationship. Clear GTM direction, clean process definitions, neutral data: those things produce trust. A reporting line is just one way of trying to get there.
Build the function right, and the chart takes care of itself.
Responsible AI in RevOps: Protecting Data While Scaling Intelligence


AI is becoming one of the most privileged users in your revenue stack.
After all, it connects signals across systems that were never designed to “talk” this freely.
The upside obviously includes faster decisions, sharper targeting, and more efficient operations. But there’s a shift happening at the same time that needs attention.
The shift is that sensitive operational intelligence is now flowing through workflows that traditional controls weren’t built to govern.
A lot of organizations are still treating AI as merely a productivity layer. In reality, it’s the new data surface that can influence business outcomes.
For RevOps, this changes the mandate as it’s no longer enough to optimize processes and maintain clean data. The function must now ensure that how AI accesses, interprets, and acts on data remains compliant, secure, and aligned with organizational risk tolerance.
When guardrails are unclear, teams either slow adoption out of caution or move forward in ways that create invisible exposure.
The companies that scale AI successfully are designing trust into how AI operates from the start, so innovation doesn’t outpace control.
This presents an important question before us! As AI becomes embedded in daily RevOps workflows, what does responsible, secure usage actually look like in practice?
AI Changes the Risk Model for RevOps
Most of us have experienced a moment where we share our phone location with a friend so they can find us at a crowded event. It’s convenient, but later you realize that you’ve effectively given someone real-time visibility into where you are until you turn it off.
AI works similarly inside RevOps. The moment AI is connected to your CRM, marketing automation, support systems, or data warehouse, it gains visibility into sensitive operational signals. The value is undeniable, but so is the responsibility.
Organizations are experiencing a record-high rise in privacy and security incidents related to artificial intelligence. According to Stanford University’s 2025 AI Index Report, AI-related incidents increased by 56.4% in just one year, with 233 cases reported across 2024.
What makes AI different from traditional tools is how it interacts with data. Instead of following predefined rules, it reads context, synthesizes information, and generates outputs that may combine signals across multiple systems. This changes the risk model from “who has access” to “how data flows.”

Consider a simple RevOps scenario. A team member asks an AI assistant to summarize pipeline risks ahead of a leadership meeting.
To do this, the system may analyze deal notes, customer emails, and internal comments, some of which contain sensitive context. Nothing malicious happened, yet sensitive information moved through a process that may not have been fully governed.
Multiply this across dozens of daily interactions, and you begin to see why traditional controls aren’t always sufficient. AI expands the surface area of operational intelligence in several ways:
- Context aggregation: Models can connect signals across systems that were previously siloed
- Continuous interaction: Every prompt becomes a potential data exchange
- Dynamic outputs: Information may be surfaced in new combinations that weren’t anticipated
- Broad visibility: Insights may reach users who didn’t previously access certain data directly
AI is not inherently risky, but the nature of risk has evolved.
RevOps sits at the center of this shift because it manages the flow of revenue-critical information. Pipeline strategy, customer lifecycle data, pricing logic, and performance metrics all pass through RevOps processes.
As AI becomes embedded, the function naturally becomes a steward of how that intelligence is handled.
Smarter teams treat this issue as part of system design. Once you start viewing AI through this lens, it becomes clear that the real question is how to ensure every interaction meets the same security and governance standards you expect everywhere else.
💡Discover how AI in Marketing Ops unlocks growth potential
Key takeaway: AI shifts risk from system access to data flow and interpretation. RevOps must understand how information moves through AI workflows to ensure compliance and security.
Where AI Introduces Hidden Compliance Gaps
Compliance risks begin with convenience. Think about how often you’ve copied a snippet of text into a tool just to “quickly get a summary.” Even an act as small as moving sensitive information into places no one is actively monitoring can introduce risk.
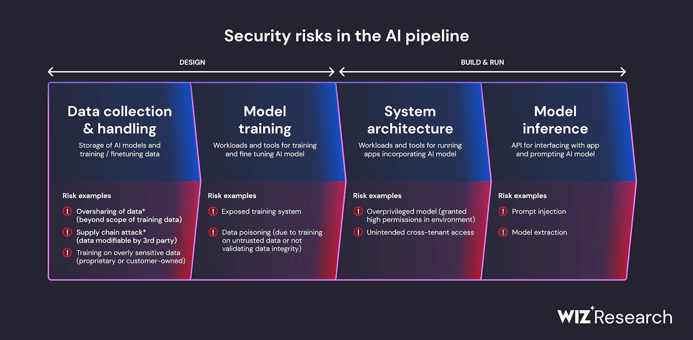
Source: Wiz
AI creates similar moments across RevOps, where small, well-intentioned interactions gradually expand the surface area of risk. The challenge is the invisible drift that it brings.
Where do these gaps tend to appear?
In practice, AI introduces risk in places that feel more operational than technical in nature.
Shadow AI usage: Teams experiment with AI tools outside approved environments to move faster. A rep uploads account data to generate messaging, and a marketer tests campaign ideas using customer segments. Meanwhile, your RevOps might not even know it’s happening.
Prompt leakage: What goes into prompts matters a lot. This includes detailed customer context, deal strategy, or internal discussions that can expose information beyond intended boundaries, especially when prompts are reused or shared.
Over-permissive integrations: AI connected to multiple systems may inherit broad access. Without careful scoping, it can retrieve more data than necessary to perform a task.
Lack of visibility into model behavior: Many organizations don’t fully understand how models process, store, or learn from interactions, creating uncertainty around data handling.
Real-life analogy: the shared document problem
Think about a shared online document that starts as a small working file. Over time, people add comments, paste sensitive notes, and share with others “just for visibility.” Months later, no one remembers who has access, yet it contains critical information.
AI workflows can evolve the same way. Without clear boundaries, helpful interactions accumulate into exposure.
The governance blind spot
These gaps rarely trigger alerts. While the traditional security controls are designed to detect unauthorized access, it’s difficult for them to keep track of unintended context sharing.
RevOps teams often assume that if systems are secure, workflows are secure. AI breaks that assumption by introducing new pathways where data can move indirectly.
This is why governance must move from controlling systems to understanding interactions.
💡A useful read - The data hygiene crisis: Leadership confidence doesn’t match reality
Why awareness isn’t enough?
Training teams to “be careful” helps, but it doesn’t scale. As AI becomes embedded in daily work, relying solely on user judgment creates inconsistency.
It’s pivotal to recognize that compliance gaps are less about intent and more about design.
And once you start mapping where these hidden gaps exist, this question becomes unavoidable - If risks emerge through everyday workflows, how do you embed guardrails that protect data without slowing the teams using AI?
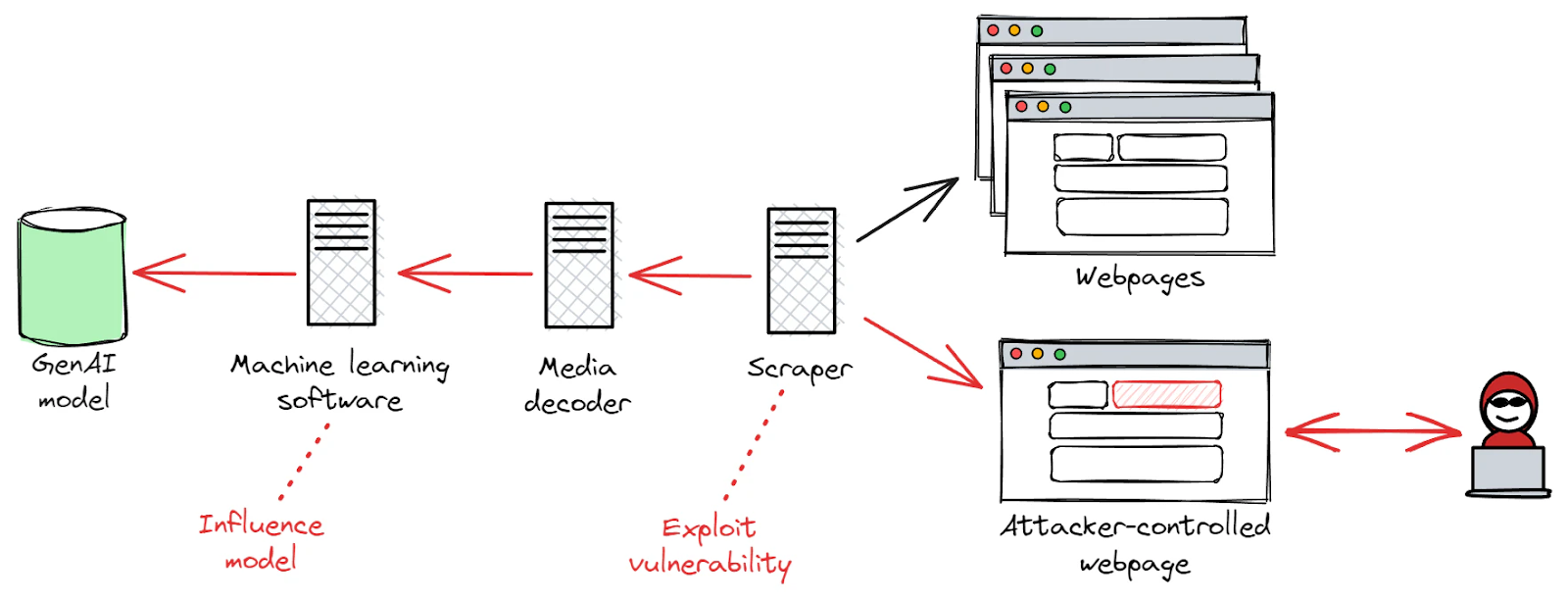
Visualization of an adversary exploiting a data scraper flaw to manipulate a GenAI model during training or fine-tuning. Source: WIZ
Key takeaway: Hidden compliance gaps often arise through routine AI interactions like prompts, integrations, and experimentation. Understanding where these gaps form is essential before designing effective guardrails.
From Policy to Practice: Embedding Guardrails in Daily Workflows
Organizations commonly respond to AI risk by writing policies that people seldom read. The real risk, however, lies in workflows.
If compliance only shows up during audits or annual training, it’s already too late for you. What’s pivotal is that guardrails are designed into how RevOps operates every day
The biggest risk is decision distortion
When people think about AI risk, they imagine leaks or breaches. But one of the least discussed risks is subtler: AI can surface insights that feel authoritative even when context is incomplete.
For example, an AI summary of pipeline health may omit nuance from deal conversations. Teams might adjust strategy based on partial interpretations, not maliciously, but because the system made it easy.
Apart from protecting data, guardrails are about protecting decision integrity.
What does embedding guardrails actually mean?
Instead of treating compliance as a separate function, leading RevOps teams design workflows where safe behavior is the default.
This includes:
- Context-aware access controls: Ensuring AI only accesses the minimum data required for each use case, rather than broad system visibility.
- Prompt boundaries: Clear guidance on what types of information should never be included in AI interactions (e.g., pricing strategy, confidential negotiations).
- Usage monitoring: Observing patterns of interaction to identify risky behavior early without policing teams.
- Explainability checks: Encouraging review of AI outputs in high-impact decisions so context isn’t lost.
These controls don’t block innovation but make experimentation safer.
Think about a shared office fridge. Generally, workplaces don’t post a 50-page policy on how to use it. Instead, there are simple norms: label your food, don’t take what isn’t yours, and clean up after yourself. The environment subtly guides behavior.
AI guardrails should work the same way. Clear expectations and structural cues prevent problems without constant oversight.
The RevOps role evolves
RevOps becomes the orchestrator of safe experimentation. The question becomes “How do we design workflows where teams can use AI confidently?”
This often requires closer collaboration with security and legal, not as gatekeepers but as partners in designing practical controls.
Another insight leaders often overlook
Guardrails increase adoption.
When teams trust that AI usage is safe and well-governed, they experiment more confidently. Without clarity, adoption slows because uncertainty creates hesitation.
How a mature AI governance actually operates
You’ll notice a few signals in organizations that get this right:
- Teams understand where AI is allowed and where it isn’t
- Sensitive workflows have additional review layers
- RevOps dashboards include visibility into AI usage patterns
- Leaders talk about AI governance as part of operational strategy
Compliance becomes part of the operating rhythm rather than an afterthought.
And once guardrails are embedded, the conversation goes from managing risk to scaling trust.
The question to tackle now is, how do you design an operating model where innovation and compliance reinforce each other instead of competing?
Key takeaway: Embedding guardrails into workflows ensures AI is used responsibly without slowing teams down. Well-designed controls protect both data integrity and decision quality.
💡Learn how to use AI to build scalable HubSpot workflows
How RevOps Scales Innovation Without Compromising Trust
By the time organizations reach this stage, the question shifts from whether to use AI to how to use it in a way that strengthens confidence both internally and externally.
Responsible AI in RevOps is more than a checklist. It’s an operating model that balances three forces: speed, insight, and control. When designed well, compliance supports innovation by removing uncertainty.
Source: Microsoft
Guardrails over gatekeeping
Traditional governance often acts as a barrier. In AI-led environments, this approach quickly becomes a bottleneck.
Guardrails work differently. They define boundaries within which teams can move freely. Instead of asking for permission every time, teams operate within clearly defined safe zones.
For example:
- Sensitive data categories are automatically masked or restricted
- Approved AI environments are clearly defined
- Usage patterns are monitored without interrupting workflows
This creates freedom with accountability.
Data lineage as a confidence layer
One of the most powerful and underappreciated concepts in AI governance is data lineage. It’s about understanding where data comes from, how it’s used, and where it flows.
When RevOps can trace how AI interacts with customer and revenue data, leaders gain confidence that insights are grounded and compliant. Transparency reduces hesitation and supports faster decision-making.
Shared ownership of responsible AI
Responsible AI cannot sit solely with security or IT. RevOps plays a critical role because it understands how workflows actually operate.
A strong model typically includes:
- RevOps defines usage patterns and operational boundaries
- Security, ensuring infrastructure, and monitoring
- Legal guiding compliance, and regulatory considerations
- GTM teams follow clear norms
Think about advanced driver assistance systems. Instead of replacing the driver, they enhance awareness, maintain boundaries, and reduce risk while the driver remains responsible.
AI should function the same way in RevOps by augmenting decisions while operating within defined limits.
Putting it together
Organizations that operationalize responsible AI focus on a few core actions:
- Define where AI is allowed to interact with sensitive data
- Establish clear prompts and usage norms
- Monitor interactions to detect anomalies early
- Build transparency into how insights are generated
Over time, this creates a culture where teams innovate confidently because the system supports safe behavior by design.
The real outcome is the trust that AI can be used to accelerate decisions without introducing hidden risk.
Key takeaway: Responsible AI becomes scalable when governance is embedded into workflows rather than layered on top. RevOps enables innovation by designing systems where speed and security coexist.
The bottom line is, AI will continue to reshape how revenue organizations operate. The advantage will go to those who design for trust from the start.
And as AI becomes more embedded in daily work, one question that will quietly define the leaders is, are your systems merely intelligent, or are they intelligently governed?

RevXpert Academy
Personalization on repeat: use HubSpot sequences to maximize outreach

Personalization isn’t just for flashy ad campaigns — it’s where HubSpot Sequences can really shine. ✨
This LMS video walks you through setting up sequences in HubSpot so you can start keeping follow-ups personal, timely, and human in no time — even when you’re running dozens at once.

Marketing Operations
We execute the technical heavy lifting—from complex integrations to attribution modeling—so you can prove campaign ROI and ensure no conversion opportunity is ever left behind.

Sales Operations
We configure your CRM and CPQ to eliminate administrative friction for reps, turning your pipeline into a source of predictable revenue rather than a guessing game.

